Spatiotemporal Graph Neural Networks for Action Segmentation in Multimodal Data


Keystep recognition is a fine-grained video understanding task that aims to classify small, heterogeneous steps within long-form videos of human activities. Current approaches have poor performance, reaching 35-42% accuracy on the Ego-Exo4D benchmark dataset.
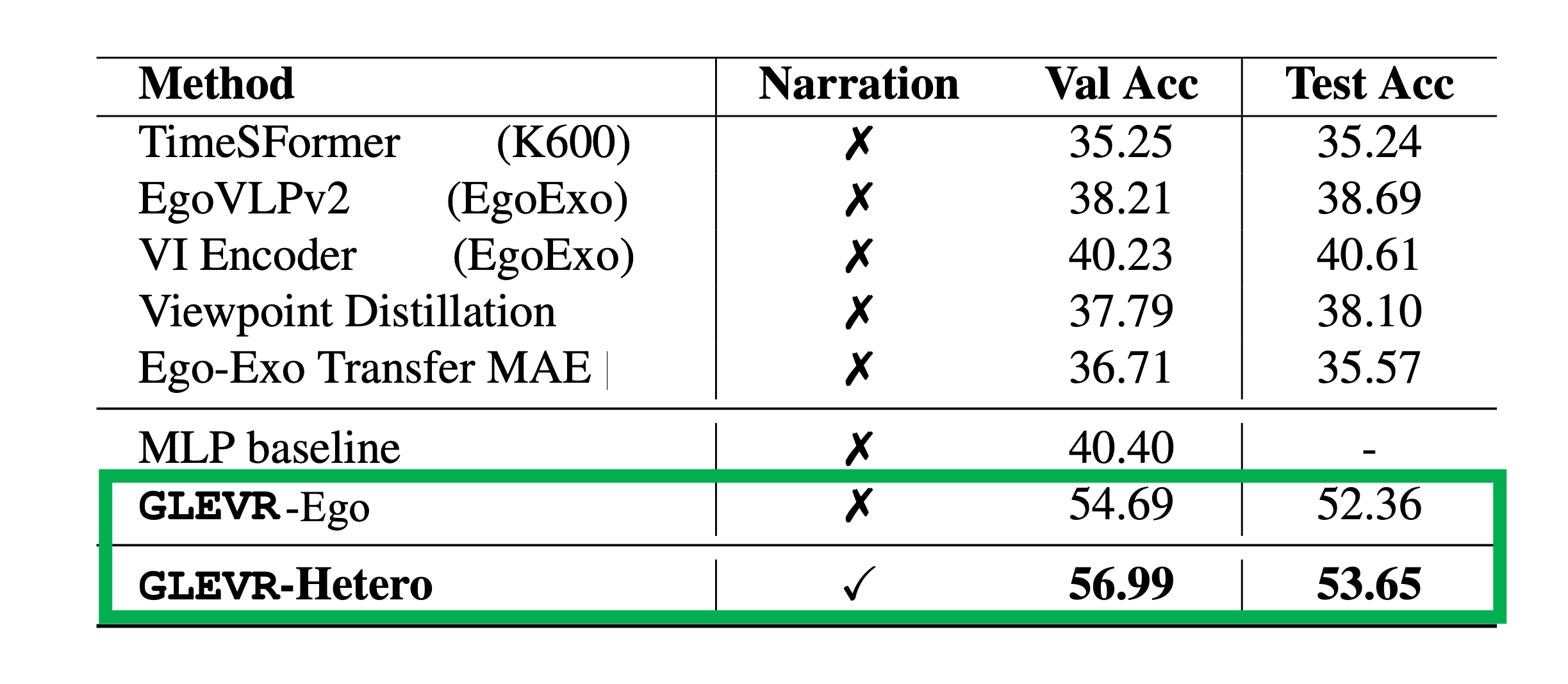
In collaboration with Intel Labs, we developed a flexible graph-learning framework for fine-grained keystep recognition that achieves state of the art performance. Our approach, termed GLEVR, consists of constructing a graph where each video clip of the egocentric video corresponds to a node. We further leverage alignment between egocentric and exocentric videos during training for improved inference on egocentric videos, as well as adding automatic captioning as an additional modality. This simple, graph-based approach is able to effectively learn long-term dependencies in egocentric videos. Furthermore, the graphs are sparse and computationally efficient, substantially outperforming larger models.
We perform extensive experiments on the Ego-Exo4D dataset and show that our proposed flexible graph-based framework notably outperforms existing methods.
GLEVR won 1st place in the 2025 Ego-Exo4D keystep recognition challenge, out of more than 20 team submissions. Check out the extended abstract on arxiv.
Check out the code repository.

Sea Ice Mapping and Uncertainty Quantification Next project
Visual Analytics for Spatiotemporal Analysis of Dengue Serotypes