Rethinking Geolocation Features in Deep Learning and Geospatial Applications

Most labeled datasets for environmental and geospatial applications, especially those that represent true “ground truth” from field measurements, are collected in fairly limited regions. Whether I am reading research papers or reviewing student proposals in my machine learning and spatial data class, I see one common mistake: adding latitude and longitude as features to machine-learning models. The trouble is that adding lat/lon does seem to improve classification, regression, or estimation performance on these limited datasets. Reported metrics go up, errors go down, and everything looks better on paper. So why do I call this a mistake? Because in many cases, the model isn’t learning the underlying environmental process at all—it’s memorizing location. It is learning how to map lat/lon to the target.
This blog post is about why that happens, why it matters, and how we can do better. The discussion draws on two recent GeoHAI Lab papers—one on dynamic air-quality estimation and another on automated sea-ice mapping—which together reveal both the failure modes and the productive uses of geolocation in deep learning.
The illusion of improvement under regional data splits
Most ground-truth labeled Earth-observation datasets are regional by construction. Air-quality monitors cluster around population centers, high-quality ice charts (maps, labels) are limited in regional coverage, and generally-speaking, labeled data rarely span the full range of environmental and geographic variability we ultimately care about. When such datasets are randomly split into training and test sets, nearby locations frequently appear in both—even if timestamps differ. Even under spatial cross-validation scenarios where testing sites are geographicallly within and close-by training sites, effectively the same thing happens: the danger of memorization.
In this setting, adding latitude and longitude naïvely almost always improves performance. But this improvement can be deceptive. The model may not be learning better physical relationships at all, it may simply be learning the mapping from latitude and longitude to the outcome, i.e., learning where certain outcomes are common.
This illusion becomes apparent only when evaluation explicitly tests geographic generalization under more extreme spatial blocking and spatial splits for testing, rather than interpolation within familiar regions.
Evidence from air quality: naïve location breaks under spatial generalization
In our recent paper, using daily PM2.5 estimation across the continental United States as the application domain, we explicitly evaluated multiple ways of incorporating geolocation into a strong Bi-LSTM + attention model that was already generating state-of-the-art results for estimating surface-level PM2.5 values. We compared models with no location, raw latitude/longitude, sinusoidal encodings, and pretrained Earth embeddings, and evaluated them under both within-region (random and spatial dropout of grount truth sitses) and out-of-region (checkerboard) spatial partitions.
The checkerboard partitioning scheme is shown below. Entire spatial blocks are held out during training, preventing geographic leakage and forcing true spatial generalization:

Under random or spatially held-out test sites, raw coordinates appeared helpful. But once entire larger regional blocks were withheld, a consistent pattern emerged: naïve latitude/longitude and sinusoidal encodings often degraded performance, mostly performing worse than models with no location at all.
This behavior is summarized in the figure below, which compares test R² and RMSE across geolocation strategies under checkerboard partitions:
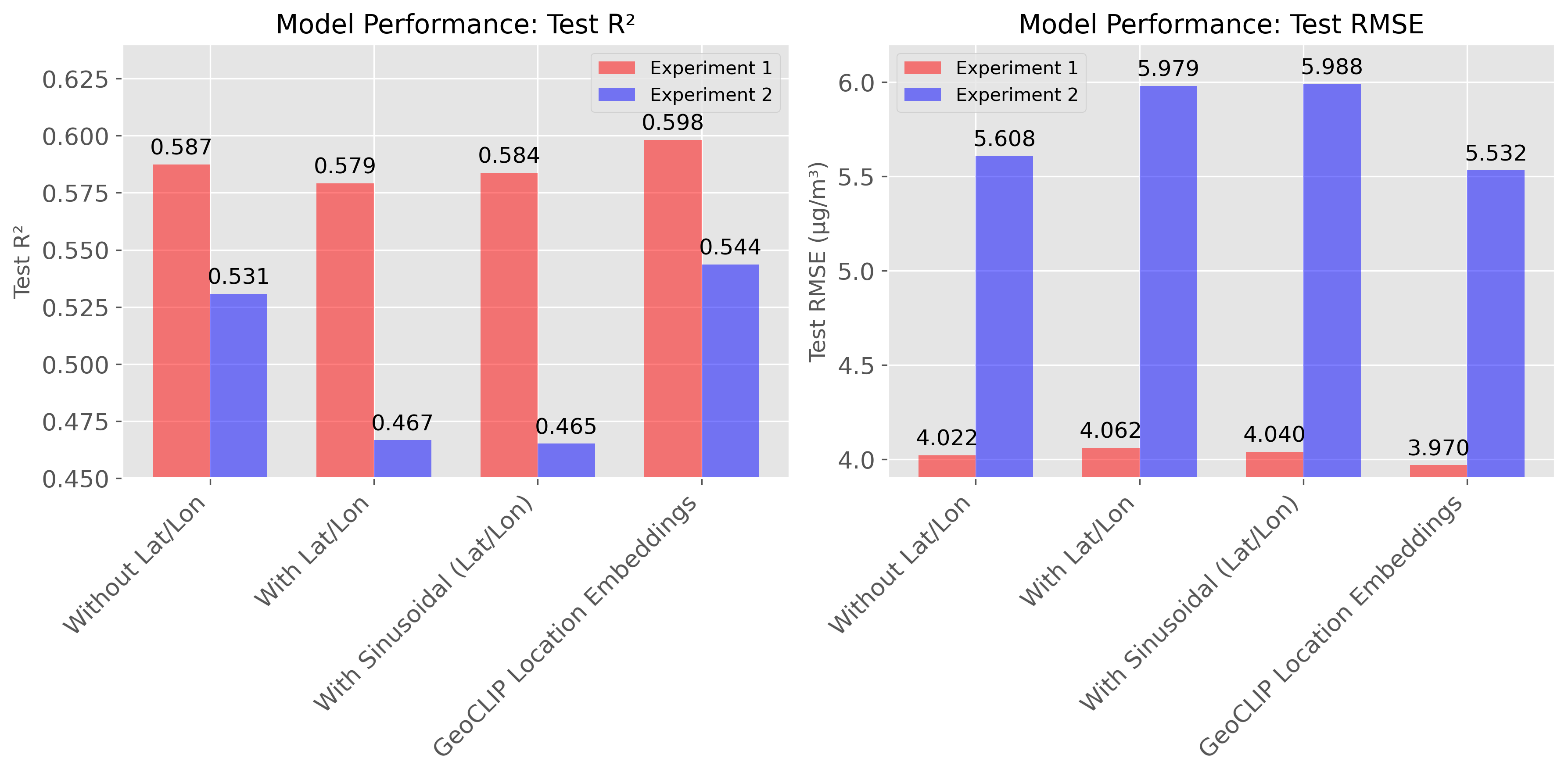
The apparent gains from raw location dissapeared when the model was forced to generalize geographically, suggesting location overfitting rather than transferable learning. The paper goes on to do more analyeses that focus on extreme and larger values during wild-fire events, which I don’t repeat here.
A warning from sea ice mapping: feature attribution reveals memorization
We observed an even more instructive and concerning pattern in our work on automated sea-ice mapping from SAR imagery. In that study, we went beyond performance metrics and explicitly analyzed how models used geolocation by applying SHAP-based feature attribution across ice classes.
At first glance, models that incorporated latitude and longitude again appeared to perform better, particularly for difficult and underrepresented ice classes. But SHAP analysis revealed what was actually happening internally.
For minority ice classes, models that included location features were paying substantially more attention to latitude and longitude than to the SAR observations themselves. In effect, the model was not learning the physical scattering signatures of those ice types. Instead, it was memorizing where those classes tended to occur in the training data, i.e., the models were learning a mappint from location to the output class.
This means the models simply won’t generalize. A model that relies on location rather than observation will fail when applied:
- to a different Arctic region,
- to the same region under other climate conditions in such a dynamic region,
- or even to future years as ice regimes shift.
In a rapidly evolving Arctic, memorizing yesterday’s geography is not the same as learning ice observation physics. The SHAP results made this distinction explicit: location was replacing observation, not supporting it.
Two domains, one common pitfall
Taken together, the PM2.5 and sea-ice domain results point to the same underlying issue. When training and evaluation data are confined to a region, location becomes a shortcut variable, hurting generalizabiltiy. Models may appear to improve, but the improvement reflects memorization rather than generalizable learning.
This effect is particularly pronounced for:
- minority or rare classes,
- extreme values,
- and application areas where earth observation signals are ambiguous or noisy.
In these cases, it is even more likely that geolocation inflates apparent performance while actively undermining .
When location does help: treating it as a prior or pretrained embeddings
The PM2.5 estimation work also analyzed a constructive alternative. The problem is not geolocation itself, but how it is incorporated.
Instead of concatenating coordinates, we treated pretrained Earth embeddings as priors, conditioning the temporal representation of the model via a Hadamard (element-wise) fusion. This design prevents the model from using location as a shortcut, while still allowing geographic context to modulate how dynamic observations are interpreted.
Conceptually, the model is asking:
Given what we know about this place, how should today’s observations be interpreted?
This approach did improve performance without lowring the influence of physical observations, and its largest gains appeared in the high-concentration tail of PM2.5, where deep-learning regression models typically struggle most.
Even concatenating frozen pretrained earth embeddings helps with performance and generalizability, albeit more experiments are required there to analyze the distribution of different location encoder embeddings and how they influence the outcome. Unfreezing the location encoder is a recipe for disaster though, as it would allow the model to perfectly overfit to locatoins, as expected.
A design principle for GeoAI
The combined lesson from these two domains is clear:
Geolocation should influence interpretation, not replace observation.
Raw coordinates and naïvely fused embeddings invite memorization under regional splits. Feature-attribution methods like SHAP make this failure mode visible, particularly for rare classes and extremes. In contrast, treating location as a prior preserves the dominance of physical signals while improving robustness and generalization.
As GeoAI models are increasingly deployed beyond their training domains—and under accelerating environmental change—this distinction becomes foundational rather than optional.
Further reading
-
Performance and generalizability impacts of incorporating location encoders into deep learning for dynamic PM2.5 estimation Karimzadeh, M., Wang, Z., & Crooks, J. L. (2025). GIScience & Remote Sensing. https://doi.org/10.1080/15481603.2025.2594797
-
Enhancing and interpreting deep learning for sea ice charting using the AutoICE benchmark Jalayer, S., Alkaee Taleghan, S., Pires de Lima, R., Vahedi, B., Hughes, N., Banaei-Kashani, F., & Karimzadeh, M. (2025). Remote Sensing of Environment. https://doi.org/10.1016/j.rse.2025.113566